



Det vanligaste problemet man stöter på som redaktör för en webbplats är att man helt ovetandes kopierar html- eller xml-kod och lägger in på sidorna. Det kan hända när man kopierar en text eller bild som ligger i ett dokument som skapats med Office-paketet, eller när man kopierar något på en webbsida. Man ser inte att man fått med koden i urklippet, utan man blir oftast medveten om att något konstigt skett med utseendet på den sida man jobbar med.

I exemplet nedan finns en text kopierad från en webbsida och det hänger med en del HTML-kod i urklippet som stör utseendet.
Exempel: Av misstag inkopierad kod
Vad som hänt på sidan kanske inte är uppenbart vid första ögonkastet, men typsnittet har plötsligt blivit Verdana isf Source Sans, storlekarna på texten är fel, färgen på rubriken och brödtexten är fel.
Så här ser det ut i admin om du klickar på fliken ”Text”.

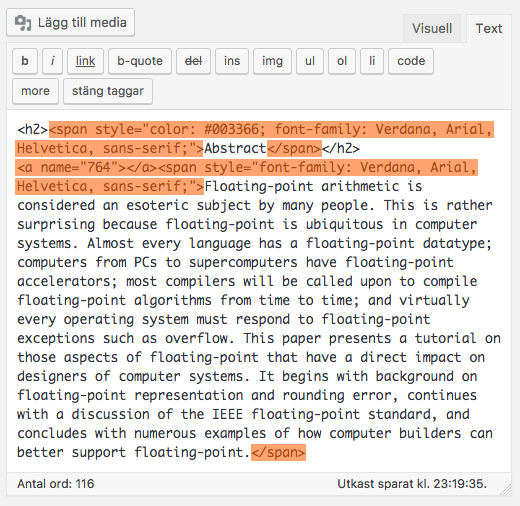
Om man väljer att rensa bort html-koden manuellt, gäller det i exemplet ovan att ta bort all kod som är markerad med orange färg.
Om man vill slippa att rensa bort koden manuellt, hur gör man då?
Metod 1
- Som Mac-användare kan du istället för att klistra in som vanligt med command+v använda command+option+shift+v då klistrar du in texten helt oformaterad.
- Som Windows-användare klistrar du in med Control+Shift+v för att klistra in oformaterad text.
- Du får sedan använda WordPress admin för att typografera texten så den ser ut som du vill.
Metod 2
- Om olyckan redan är skedd och man vill rensa bort koden slunkit med finns det två metoder. Antingen att prova verktyget ”Rensa formateringen” som har ett suddgummi som symbol ELLER att manuellt rensa bort den inkopierade koden. Suddgummit lyckas ofta rensa bort det mesta, men hjälper inte det så är det manuell rensning som gäller.

Ska du använda suddgummit börja med att klicka på fliken ”Visuell” och markera sedan all text och klicka sedan på suddgummit. Klart. Kontrollera resultatet genom att klicka på fliken ”Text” och se om koden försvunnit.

Metod 3
- Om du kopierat text ur ett dokument eller en sida som du misstänker innehåller kod kan du använda verktyget till vänster om suddgummit, ”Klistra in som text”.

Ska du använda ”Klistra in som text” börjar du med att kopiera texten i ditt dokument, gå sedan till din artikel i admin och klicka på fliken ”Visuell” om du inte redan är i den. Klicka sedan på ”Klistra in som text” och klistra sedan in ditt urklipp. Detta fungerar mycket bra, men alla rubriker i ditt urklipp är förvandlade till brödtextrader som du efteråt får markera och göra rubriker av igen.
Problemet beskrivet ovan är inte specifikt för WordPress utan förekommer i de flesta system och hänger samman med att urklipp som görs får med originaldokumentets formatering.